
Rolling Update Kubernetes : déployer sans interruption de service
Dans un monde où la disponibilité des services est devenue un enjeu stratégique, certaines organisations ne peuvent pas se permettre la moindre interruption. Pour des applications critiques dans des secteurs comme la finance, la santé ou le commerce en ligne, chaque seconde d’indisponibilité peut avoir des conséquences graves : pertes financières, dégradation de l’expérience utilisateur, voire impacts majeurs pour les utilisateurs finaux.
Le déploiement d’une nouvelle version applicative représente un réel défi pour garantir une haute disponibilité en continue. Heureusement, Kubernetes propose des mécanismes avancés pour simplifier ces opérations complexes. Parmi eux, la stratégie de Rolling Update se distingue en permettant un remplacement progressif des pods en ancienne version par ceux avec la nouvelle, tout en maintenant le service opérationnel sans interruption.
Dans cet article, nous explorerons en détail la stratégie de déploiement en Rolling Update. Nous analyserons également son fonctionnement et les bonnes pratiques pour assurer un déploiement fluide.
Les stratégies de déploiement sans interruption de service
Déployer une nouvelle version d’une application sans provoquer d’interruption de service est un défi majeur et n’est pas toujours réalisable. Techniquement, déployer une nouvelle version d’une application en maintenant la disponibilité du service nécessite un arrêt relance sans affecter les utilisateurs ou les clients connectés. Les stratégies les plus probantes pour y parvenir sont les suivantes :
- Blue-Green Deployment
- Rolling Update
Blue-Green Deployment
Cette stratégie consiste à maintenir deux environnements identiques, appelés « blue » et « green ». L’un d’eux est actif (blue) tandis que l’autre (green) est inactif. Lorsqu’une nouvelle version de l’application est prête, elle est déployée sur l’environnement inactif. Une fois le déploiement terminé, le trafic est redirigé vers l’environnement mis à jour. Cela permet de revenir rapidement à la version précédente en cas de problème.
Rolling Update
Cette stratégie repose sur une mise à jour progressive des instances de l’application. Plutôt que de déployer la nouvelle version sur toutes les instances simultanément, elle est appliquée à un nombre limité d’instances à la fois. Cela réduit l’impact potentiel d’une mise à jour défectueuse, mais allonge la durée totale du déploiement. En cas de problème, le retour à la version précédente suit le même processus progressif.
Analyse des deux stratégies
En lisant ces définitions, vous comprenez que ces stratégies s’adressent à des services accessibles via le réseau, et quelles ne sont pas adaptées à toutes les applications.
Par exemple, une application de type batch ne peut pas être mise à jour sans interruption de service, car elle nécessite souvent un temps d’arrêt pour finaliser proprement les traitements en cours. De même, appliquer de telles stratégies pour une monté de version d’un serveur de base de données pourrait entraîner des pertes de données.
La seule solution qu’il vous reste est de concevoir une architecture applicative, ou la faire évoluer pour qu’elle soit compatible avec l’une de ces stratégies de déploiement. Pour cela, vous pouvez notamment vous inspirer des serveurs Web stateless qui sont parfaitement adaptés à ces stratégies.
Déploiement Rolling Update avec Kubernetes
Kubernetes est un orchestrateur de conteneurs qui prévoit une ressource Deployment pour gérer les pods de notre application. Cet objet Kubernetes permet de déployer, mettre à jour et gérer des applications conteneurisées de manière déclarative.
Un Deployment nous permet de définir l’état souhaité de notre application en appliquant la stratégie de déploiement la plus adaptée. Kubernetes supporte deux stratégies de déploiement :
- Recreate : tous les pods sont arrêtés avant de déployer la nouvelle version.
- Rolling Update : les pods sont mis à jour progressivement.
La stratégie du Recreate entraîne irrémédiablement une interruption de service. En revanche, la stratégie du Rolling Update est parfaite pour atteindre notre objectif de déploiement sans interruption de service.
Analyse du comportement lors d’un Rolling Update
Le concept de déploiement en Rolling Update est simple à comprendre et promet de déployer une nouvelle version d’une application sans interruption de service. Cependant, qu’en est-il réellement ? Que se passe-t-il au sein d’un cluster Kubernetes lors d’un déploiement en Rolling Update ? Quels sont les impacts sur l’application et le service ?
Pour répondre à ces questions, nous allons créer un exemple simple d’application Web _stateless_ et l’exécuter sur un cluster Kubernetes. Nous allons ensuite déployer une nouvelle version de cette application en utilisant la stratégie de déploiement en Rolling Update.
Comment analyser le comportement d’un Rolling Update ?
La stratégie de déploiement en Rolling Update prévoit de mettre à jour progressivement les pods d’une application. Il peut donc y avoir plusieurs pods en cours d’exécution avec des versions différentes de l’application. Pour vérifier cette hypothèse, l’application Web que nous allons développer exposera un endpoint affichant la version de l’application et le nom de l’hôte sur lequel elle s’exécute.
Par ailleurs, nous devons créer un programme client qui interroge l’application Web à intervalles réguliers afin d’obtenir le couple version/nom d’hôte. Il sera donc possible d’analyser ces données pour comprendre le comportement de l’application pendant le déploiement en Rolling Update.
L’application serveur Web
Nous allons créer une application Web très simple pour tester notre hypothèse. Cette application exposera un endpoint HTTP qui retourne un objet JSON contenant la version de l’application et le nom de l’hôte. Pour cela, nous allons coder un serveur Web Node.js qui s’appuie sur le framework Express.js.
Afin de simplifier notre expérimentation, la version de l’application et le nom d’hôte seront définis par des variables d’environnement. En effet, le Deployment Kubernetes de l’application Web sera modifié pour injecter ces variables d’environnement dans le conteneur de l’application et simulera ainsi le déploiement d’une nouvelle version de l’application en remplaçant progressivement les pods correspondant à la nouvelle configuration.
Préparation du projet
Commençons par créer un projet Node.js et installons les dépendances nécessaires :
$ mkdir server
$ cd server
$ npm init -y
Wrote to ./package.json:
{
"name": "server",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"description": ""
}
$ npm install express
added 66 packages, and audited 67 packages in 6s
14 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilitiesPour bénéficier de la syntaxe moderne de JavaScript, nous créerons un fichier index.mjs qui contiendra le code de notre application. Nous devons donc modifier le fichier package.json de la manière suivante :
// /server/package.json
// ...
"version": "1.0.0",
- "main": "index.js",
+ "main": "index.mjs",
"scripts": {
// ...Le code de l’application
Nous créons le fichier index.mjs et y ajoutons le code suivant :
// /server/index.mjs
import express from 'express';
const app = express();
const port = process.env.PORT || 3000;
app.get('/', (_, res) => {
res.send({
version: process.env.VERSION || '0.0.1-alpha',
host: process.env.POD_NAME || 'localhost',
});
});
app.listen(port, '0.0.0.0', () => {
console.log(`App listening on port ${port}`);
});Ce code source est très simple. Il renvoie l’objet JSON souhaité lorsqu’il reçoit une requête HTTP GET sur le chemin /. Le contenu de cet objet JSON est défini par les variables d’environnement VERSION et POD_NAME ou des valeurs par défaut si elles ne sont pas définies.
Création de l’image Docker
Après avoir validé l’application en local, nous allons créer une image Docker de l’application pour la déployer sur Kubernetes. Nous créons donc un fichier Dockerfile à la racine du projet avec le contenu suivant :
# /server/Dockerfile
FROM node:22
EXPOSE 3000
ENV POD_NAME=docker
ENV PORT=3000
ENV VERSION=1.0.0-${POD_NAME}
# Add user for K8S deployment
RUN useradd appuser \
&& usermod -a -G root appuser \
&& mkdir -p /home/appuser \
&& mkdir -p /opt/app \
&& chown appuser /home/appuser
# Add files and set permissions
WORKDIR /opt/app
COPY package.json package-lock.json index.mjs /opt/app/
RUN chown -R appuser:root /opt/app
USER appuser
RUN npm install
CMD ["node", "index.mjs"]Vous pouvez ensuite créer l’image Docker de l’application Web avec la commande suivante :
# Dans le répertoire /server
$ docker build -t demo-app:1.0.0 .Création du client
Nous allons créer un client qui interroge l’application Web à intervalles réguliers. Ce client sera exécuté sur notre machine locale et interrogera l’application Web déployée sur Kubernetes. Ce programme doit collecter les réponses de l’application Web et les fusionner dans un tableau qui sera enregistré dans un fichier JSON. Pour cela, je vous propose de créer un programme Python qui appelle le endpoint de l’application Web en simulant une forte sollicitation du service grâce à une boucle exécutée par de multiples workers.
Préparation du projet
Commençons par créer un projet Python et installons les dépendances nécessaires :
$ mkdir client
$ cd client
$ python3 -m venv venv
$ . venv/bin/activate # <1>
$ pip install aiohttpActivation de l’environnement virtuel Python sous Linux/MacOS, utiliser venv\Scripts\activate sous Windows.
Le code du client
Nous créons le fichier main.py et y ajoutons le code suivant :
# /client/main.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
import asyncio
import json
import logging
import time
import sys
import aiohttp
class Program:
"""Programme principal"""
def __init__(self, url, workers=50):
self._url = url
self._workers = workers
self._stats = []
self._running = False
@property
def stat(self):
"""Statistiques de la dernière exécution"""
return list(self._stats)
def stop(self):
"""Arrête le programme"""
self._running = False
async def _execute_task(self, worker_id):
"""Exécute une tâche de récupération des infos des pods dans une coroutine"""
async with aiohttp.ClientSession() as session:
while self._running:
start = time.time()
data = {
"worker_id": worker_id,
"start": start,
"duration": time.time() - start,
}
try:
async with session.get(self._url, verify_ssl=False) as response:
data["status"] = response.status
if response.status == 200:
data.update(await response.json(encoding='utf-8'))
except aiohttp.ClientError as e:
data["status"] = -1
logging.error("HTTP Client exception in worker %s: %s", worker_id, e)
except Exception as e:
data["status"] = -2
logging.exception("Error in worker %s: %s", worker_id, e)
raise
finally:
data["duration"] = time.time() - start
self._stats.append(data)
async def execute(self):
"""Exécute le programme en exécutant des tâches dans différents workers"""
self._running = True
# Création des tâches
tasks = [self._execute_task(id_) for id_ in range(self._workers)]
self._stats = []
await asyncio.gather(
*tasks,
)
def write_stats(stats, fp):
"""Écrit les statistiques dans un fichier JSON"""
json.dump(
stats,
fp,
indent=2,
ensure_ascii=True,
)
fp.flush()
if __name__ == "__main__":
# Options de la ligne de commande
parser = argparse.ArgumentParser()
parser.add_argument(
"-u",
"--url",
type=str,
required=True,
help="URL to send requests to",
)
parser.add_argument(
"-w",
"--workers",
type=int,
default=50,
help="Number of concurrent workers",
)
parser.add_argument(
"-o",
"--output",
type=str,
default="-",
help="Output file (default: stdout)",
)
namespace = parser.parse_args()
# Paramétrage du programme
p = Program(
namespace.url,
workers=namespace.workers,
)
# Exécution du programme jusqu'à l'interruption par Ctrl-C
try:
asyncio.run(p.execute())
except KeyboardInterrupt:
p.stop()
# Écriture des statistiques dans le fichier de sortie
if namespace.output != "-":
with open(namespace.output, "w", encoding='utf-8') as f:
write_stats(p.stat, f)
else:
write_stats(p.stat, sys.stdout)Ce code Python collecte les réponses de l’application Web et les associe à un identifiant de worker, le timestamp de la requête et la durée de la requête. Il enregistre ces données dans un tableau qui est ensuite écrit dans un fichier JSON.
Déploiement de l’application sur Kubernetes
Nous allons maintenant déployer l’application Web sur Kubernetes. Afin de simplifier la procédure de déploiement, nous allons créer un Helm Chart qui contiendra la définition de l’application Web. Par ailleurs, les variables d’environnement VERSION et POD_NAME seront injectées dans le conteneur de l’application Web via le fichier de configuration du Deployment Kubernetes. Leurs valeurs pourront être surchargées grâce à l’utilisation de fichiers de valeurs Helm.
Création du Helm Chart
Commençons par créer la structure de notre Helm Chart avec la commande helm create. Puis supprimons les fichiers et répertoires inutiles pour ne conserver que les templates deployment.yaml et service.yaml. Nous supprimons également les variables inutiles du fichier values.yaml et ajoutons les variables permettant de configurer la variable d’environnement VERSION dans le conteneur de l’application Web. Voici la structure du projet :
helm/
├── Chart.yaml
├── templates
│ ├── deployment.yaml
│ ├── _helpers.tpl
│ └── service.yaml
└── values.yamlLes fichiers templates
Nous allons modifier le fichier templates/deployment.yaml pour y injecter les variables d’environnement VERSION et POD_NAME dans le conteneur de l’application Web. Voici le contenu du fichier :
# /helm/templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-app
labels:
{{- include "helm.labels" . | nindent 4 }}
spec:
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
replicas: {{ .Values.replicaCount }}
selector:
matchLabels:
{{- include "helm.selectorLabels" . | nindent 6 }}
template:
metadata:
labels:
{{- include "helm.selectorLabels" . | nindent 8 }}
spec:
{{- with .Values.imagePullSecrets }}
imagePullSecrets:
{{- toYaml . | nindent 8 }}
{{- end }}
containers:
- name: demo-app
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
imagePullPolicy: Always
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
env:
- name: PORT
value: {{ .Values.service.port | quote }}
- name: VERSION
value: {{ .Values.app.version | quote }}
- name: POD_NAME # <1>
valueFrom:
fieldRef:
fieldPath: metadata.name
ports:
- name: http
containerPort: {{ .Values.service.port }}
protocol: TCP
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: httpLe nom du pod est configuré à partir des métadonnées du pod Kubernetes. Cela permet d’injecter le nom du pod (nom d’hôte) dans la variable d’environnement POD_NAME. Ainsi, l’application Web pourra retourner le nom du pod dans sa réponse HTTP.
Le fichier templates/service.yaml contient la définition suivante :
# /helm/templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: {{ include "helm.fullname" . }}
labels:
{{- include "helm.labels" . | nindent 4 }}
spec:
type: {{ .Values.service.type }}
ports:
- port: {{ .Values.service.port }}
targetPort: http
protocol: TCP
name: http
selector:
{{- include "helm.selectorLabels" . | nindent 4 }}Ajout des variables à surcharger
Nous devons maintenant ajouter la variable Helm app.version dans le fichier values.yaml afin de pouvoir la surcharger lors du déploiement de l’application. Le fichier values.yaml doit donc contenir les lignes suivantes :
# Default values for helm.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
replicaCount: 4
imagePullSecrets: []
nameOverride: "demo-app"
fullnameOverride: "demo-app"
image:
repository: demo-app # <1>
tag: "1.0.0"
service:
type: ClusterIP
port: 3000
app:
version: '0'Remplacez demo-app par le nom de votre image Docker déployée sur le registre Docker.
Maintenant, il est possible de créer deux fichiers de valeurs Helm pour surcharger la version de l’application Web. Le premier fichier values-v1.yaml contiendra la version 1 de l’application Web, et le second fichier values-v2.yaml contiendra la version 2 de l’application Web. Voici le contenu de ces fichiers :
app:
version: '<numero-de-version>' # <1>Remplacez <numero-de-version> par 1 ou 2 selon le fichier de valeurs.
Configurer Kubernetes
Pour déployer l’application Web sur Kubernetes, rien de plus simple. Il suffit d’exécuter la commande suivante :
$ helm template helm/ -f helm/values-v1.yaml | kubectl apply -f - # <1> <2>La commande helm template génère la configuration Kubernetes à partir du Helm Chart et des valeurs spécifiques à la version 1 de l’application Web.
Si vous souhaitez déployer l’application Web sur un autre namespace, vous devez ajouter l’option -n <namespace> à la commande kubectl apply.
Après quelques secondes, les pods de l’application Web devraient être démarrés et répondre convenablement à la requête HTTP GET sur le chemin /. Vous pouvez vérifier que votre application Web fonctionne correctement en exécutant la commande suivante :
$ curl -v ${SERVICE_URL} # <1>
{"version":"1","host":"<nom-du-pod>"}Remplacez ${SERVICE_URL} par l’URL vers votre service Kubernetes selon la méthode d’exposition choisie.
Expérimentation du déploiement en Rolling Update
Collecter les données durant un déploiement
Notre application Web est maintenant déployée et opérationnelle sur Kubernetes, et notre client est prêt à interroger l’application Web pour collecter les données. Nous allons donc lancer le script Python pour interroger le service Web en parallèle du déploiement de la version 2 de l’application. Pour cela, nous allons exécuter la commande suivante dans un terminal :
$ cd client
$ . venv/bin/activate # <1>
$ python3 main.py --url ${SERVICE_URL} --output stats.json # <2>Pensez à activer l’environnement virtuel Python si ce n’est pas déjà fait.
Remplacez ${SERVICE_URL} par l’URL vers votre service Kubernetes selon la méthode d’exposition choisie.
Ouvrons maintenant un autre terminal et déployons la version 2 de l’application Web avec la commande suivante :
$ helm template helm/ -f helm/values-v1.yaml | kubectl apply -f -Ce déploiement va modifier la configuration du Deployment Kubernetes de l’application Web pour injecter la variable d’environnement VERSION avec la valeur 2. Kubernetes va donc procéder à un déploiement en Rolling Update de l’application Web en remplaçant progressivement les pods utilisant la variable d’environnement VERSION avec la valeur 1 par ceux utilisant la variable d’environnement VERSION avec la valeur 2.
Attendez la fin du déploiement et arrêtez le client Python en appuyant sur Ctrl-C (consultez le tableau de bord Kubernetes ou utilisez kubectl pour suivre le déploiement). Vous obtiendrez un fichier JSON contenant les réponses de l’application Web pendant le déploiement. Voici un extrait du fichier JSON :
[
{
"worker_id": 9,
"start": 1745914411.5577424,
"duration": 0.251723051071167,
"status": 200,
"version": "1",
"host": "demo-app-65f9876dc9-ps26j"
},
{
"worker_id": 3,
"start": 1745914411.5567415,
"duration": 0.25272393226623535,
"status": 200,
"version": "1",
"host": "demo-app-65f9876dc9-twmlb"
},
{
"worker_id": 0,
"start": 1745914411.5567415,
"duration": 0.25655412673950195,
"status": 200,
"version": "1",
"host": "demo-app-65f9876dc9-kn9lz"
},
// ...
]Analyse des données collectées
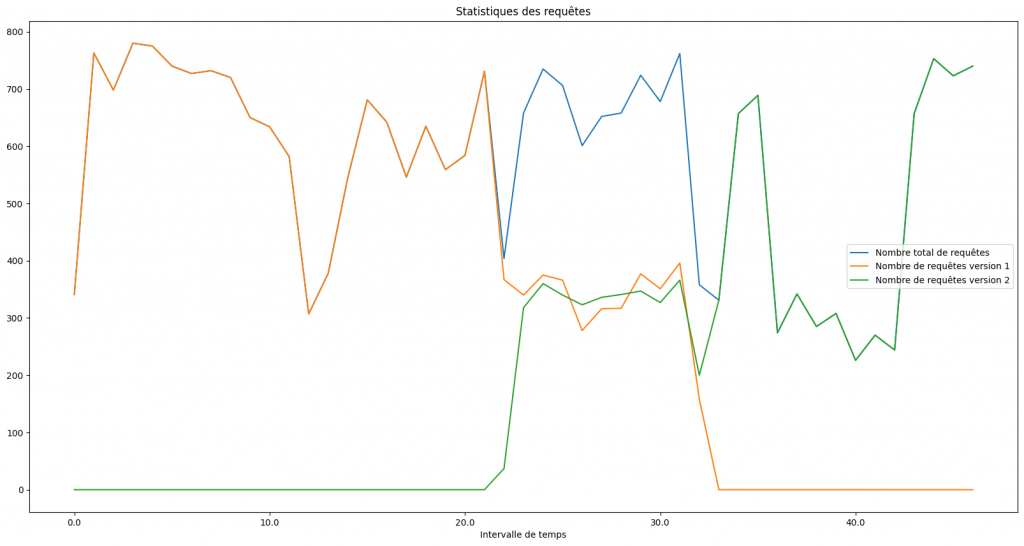
Ce premier graphique montre l’évolution de la version retournée par l’application Web durant le déploiement. On constate qu’avant le déploiement, l’application Web retournait la version 1. Puis, durant une dizaine de secondes, Kubernetes fait coexister les deux versions de l’application Web. Enfin, une fois le déploiement terminé, l’application Web ne retourne plus que la version 2.
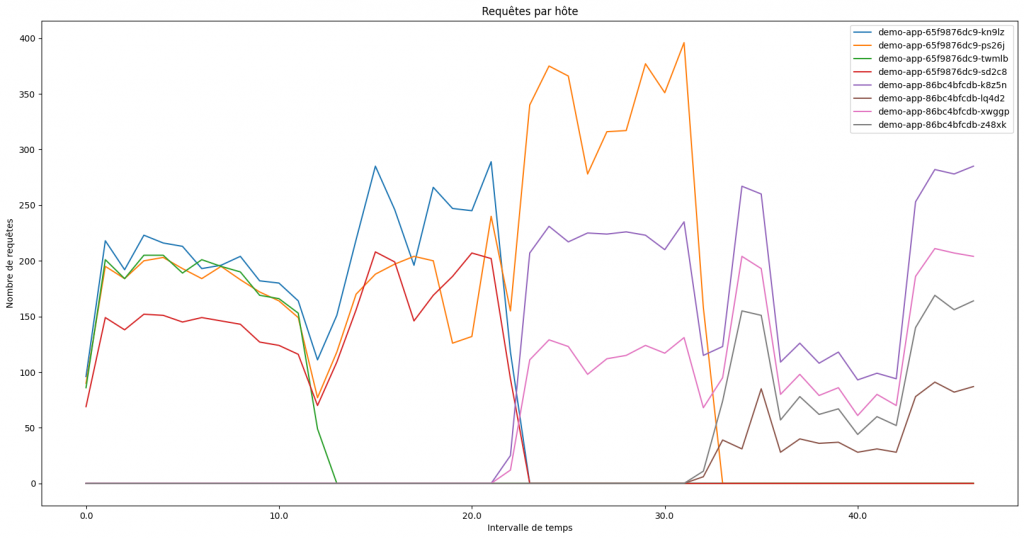
Ce second graphique montre l’évolution des pods hébergeant l’application Web durant le déploiement. On constate que :
- Kubernetes essaye de maintenir le maximum de pods opérationnels durant le déploiement (il cible 4 pods).
- Certains pods arrêtent de répondre au requêtes avant d’être remplacés par d’autres.
En mettant en relation ces deux graphiques, on constate que les remplacements de pods et la version retournée par le service Web changent en même temps (durant la période de 21 à 33 secondes). Cela signifie que Kubernetes a remplacé les pods de l’application Web en cours d’exécution par de nouveaux pods avec la nouvelle version de l’application Web. Ce qui correspond au comportement attendu d’un déploiement en Rolling Update et confirme notre hypothèse !
Conclusion
Le déploiement en Rolling Update avec Kubernetes est une stratégie puissante pour garantir une mise à jour progressive des applications sans interruption de service. Cependant, pour en tirer pleinement parti et assurer un déploiement fluide, il est essentiel de respecter certaines bonnes pratiques dont le succès repose avant tout sur une conception robuste de l’application. Voici quelques bonnes pratiques à suivre :
- Applications Stateless : Concevez vos applications pour qu’elles soient stateless, c’est-à-dire qu’elles ne conservent pas d’état local. Cela permet aux pods d’être interchangeables, et donc remplaçables sans impact sur le service.
- Compatibilité avec un Load Balancer : Assurez-vous que votre application répond correctement aux clients lorsque le trafic entrant est géré par un équilibreur de charge et est réparti entre les pods existants et les nouveaux.
- Compatibilité entre versions : Garantissez une compatibilité parfaite entre les versions N et N+1 de votre application pour éviter tout comportement inattendu pendant le déploiement.
- Endpoints de santé : Implémentez des endpoints
livenessProbeetreadinessProbepour permettre à Kubernetes de savoir quand un pod est prêt à recevoir du trafic et est en bonne santé.
Avec ces éléments en place, vous pourrez garantir une haute disponibilité de vos services, même lors des mises à jour les plus critiques. Alors, n’attendez plus ! Testez un déploiement en Rolling Update sur votre cluster Kubernetes et partagez votre expérience en commentaire.